This has been an interesting week, not only because there was a lot of walking around and polishing the interface of Yarn search, and eventually shipping it last Saturday. But also because there was a lot of thinking towards the way to organise the library that should work with multiple frameworks. However I have the feeling I can’t write my findings with that down clearly, since there are a lot of questions in that regard.
Regarding the Yarn website first there were some interesting small improvements (fully i18n, faster build, making the search bar more noticeable and fiddling with the border etc.), for which I really want to thank James Kyle, who found new things to notice every time he said something, and thus made it a better result. In the end it got merged in #383, Saturday morning (Friday evening in the US). As soon as I saw the news waking up I made a small gif and tweeted about it, which definitely “took off” to my standards.
🎉 https://t.co/BdkV4mw8Vg 🎉 check out the new search available everywhere pic.twitter.com/IvorEaCzN1
— Haroen Viaene (@haroenv) February 25, 2017
But what took off even more was the search queries. Let’s take a look at this graph:
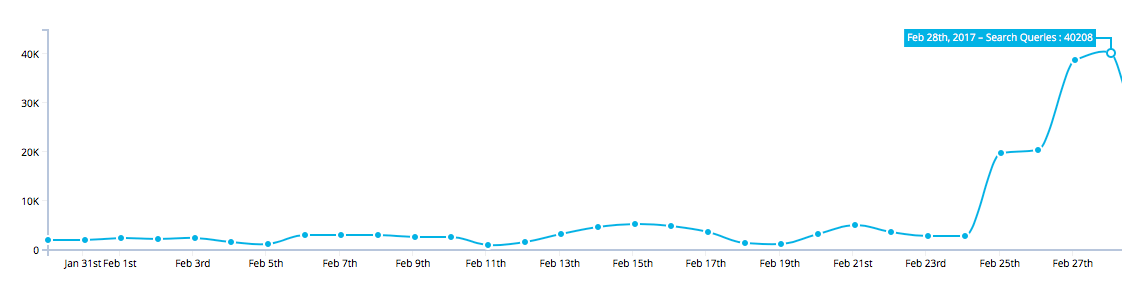
We see that instead of the usual 1000 searches in the weekend, we are getting about 20000, monday was even more impressive with close to 40000 searches. Let’s hope this growth stays, but even if it would calm down, I’m pretty sure the status quo would still be above the regular numbers.
I’ve noticed some best practices (thanks to Kevin Granger), which you can see integrated in Yarn first, and that same day also became part of react-instantsearch (via #1999). The changes might not look that impressive, but they have a huge impact on experience. And by doing the small things great, we add a lot of value to everyone! Here’s a small comparision gif for an iPad in the iOS simulator:
| before | after |
|---|---|
 |  |
Furthermore I’ve done a few other PR’s to react-instantsearch this week (#2011, #2007) and did some research on how to make sure our library will handle code-splitting correctly (#1725 (comment)).
As a last thing I noticed that there are lots of packages on npm/yarn that don’t have a description in their package.json. Because we use the description from that field, it gets served by npm as the first part of the README when it’s not available. That ususally looks pretty bad, since that’s often filled with images and things like that. The npm website avoids having a problem with that because it renders it as html in the description page. This doesn’t work in our layout at all for two reasons.
The first is security: rendering user-generated html/markdown can allow a lot of evil things, we don’t want to have that available just by searching. Christoph Pojer (Facebook) was insisting on not rendering the description even before this version, and I definitely agree with this vision.
The second reason is pretty simple. Rendering images, headers and other html features would look bad in a otherwise text-based interface.
As a (temporary) solution I sent about 30 pull requests to projects that don’t have a description to add the description they had on GitHub, which should then be reused. Amongst which a package which is part of jest, a testing framework (used) by Facebook as well as lots of other people. I’m thinking of a few strategies how to address the issue here, which might be pretty hard, since the api used to replicate all packages to Algolia (project) doesn’t differ between a description generated from a package.json and one from the README. We might have to detect the presence of html/markdown and then strip it out completely.