Ah, I’ve been so busy that I forgot to write a blogpost last weekend, but I’m doing it now. First a small update on the usage of Yarn; it’s going pretty stable, which I like.
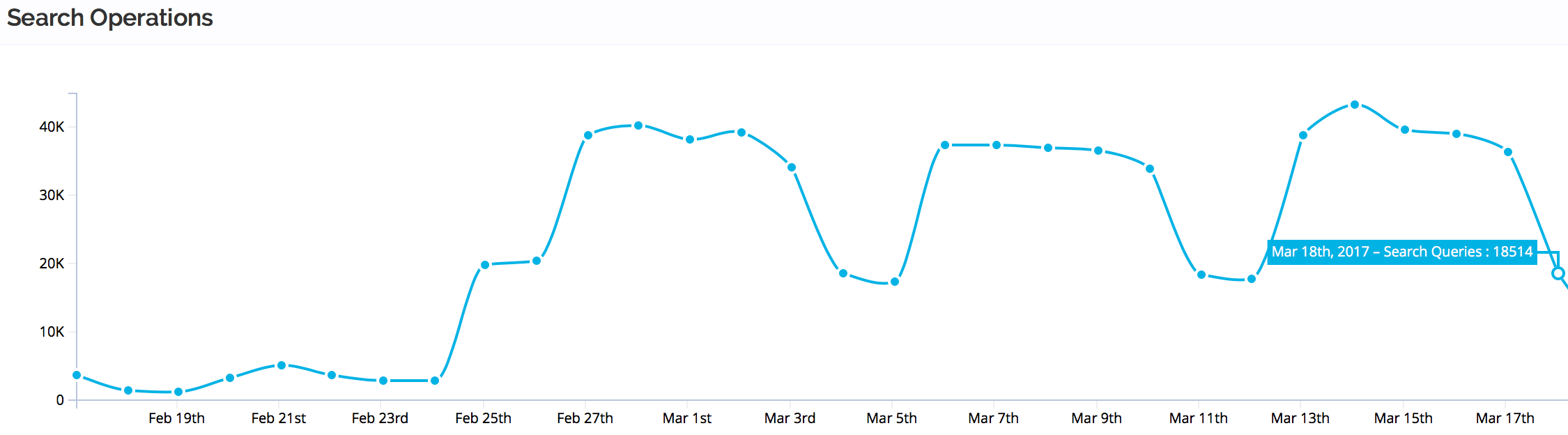
My colleague Marie was at React Conf in San Fransico Monday and Tuesday, and during her talk she mentioned that we at Algolia are making the search for Yarn in her talk about React-Storybook, which caused the slightly higher uptick Tuesday.
I worked mostly together with Ray on the upcoming vue-instantsearch, which will use my new abstraction layer. I would like the structure to look something like this:

This is a similar structure to Redux. There’s a store, which is a simple JS object. It contains the current refinements in one hand, and the result on the other hand. You use this data to render the user interface, which are the results, but also the current refinements, the time it took to process this query.
You can then change this data with so called actions. These actions then act on the current state and change it to return the new state. Its function signature looks something like this: (previousState, action) => state. In these actions you don’t mutate the current state, but create a new state, based on the previous state.
Either immediately, or with a batching algorithm, the current refinements then get transformed into props for the Algolia REST API. algoliasearch-client-javascript will be used directly, instead of the helper for two reasons. The first is to keep things light and simple to reason on. The second is because the helper is treated as a black box usually, and bundlers aren’t able to grab out only the parts that are needed. See also tree shaking for more information on that process.
When the API call is returned by Algolia, another action is dispatched with the new results. This then updates the store with the new data.
Outside of that I’ve worked on finishing the Yarn detail page. Apart from internationalisation, I’m pretty sure that I’m ready to open a pull request for that. Really excited to see what the community reaction will be to my work.
You can see a preview of my work while waiting on it to be public.
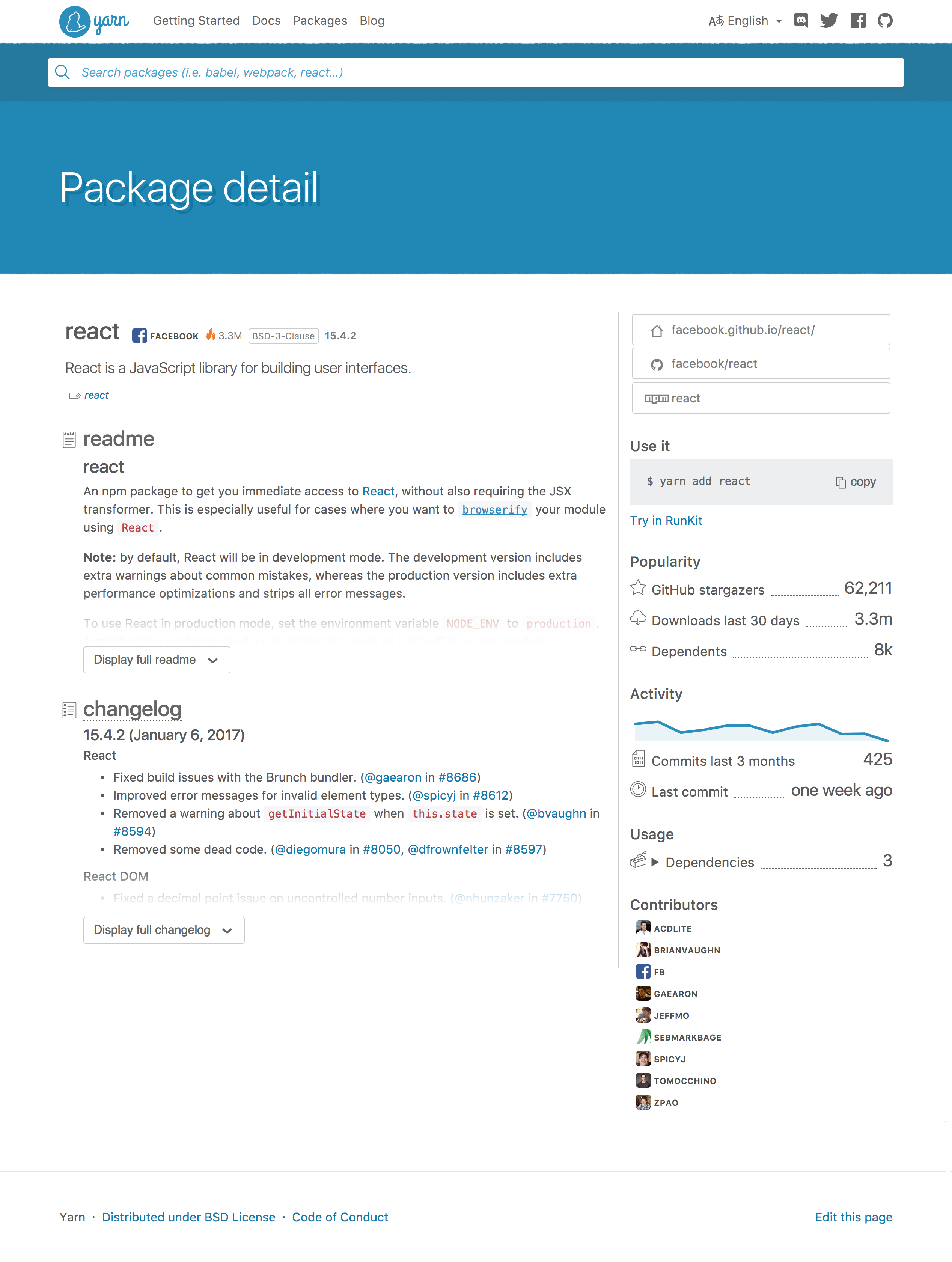
There are a few different data sources used. Most is coming from npm via replicate.npmjs.com. The dependents of each package have /_design/app/_view/dependedUpon? as a source, which is a specific couchdb view. You can read the source at algolia/npm-search. The README of packages is stored in npm, and replicated verbatim in the Algolia index, but the changelog isn’t. There are a lot of possible filenames for those, so at indexing time we check which is responding, and which is returning 404. You can read that logic in ./github.js.
We also fetch some data frontend. As said earlier, only the URL of the changelog is stored, because those are usually really big files. The activity and stargazers are fetched from the GitHub API in two separate requests. The GitHub API has a rate limit of 60 requests per minute, which is reasonable to use at frontend without being logged in. I would prefer to have the current GitHub user, and send those requests logged in, since then you can send 5000 requests per minute, which is more than enough. We however can’t do that without showing an OAuth dialog, which is a subpar experience.
The GitHub API has another slight quirk, and that’s using HTTP status 202. This is used in the activity response when the data hasn’t been computed yet. Instead of making the request take a long time and maybe timeout, they choose to send that response with an empty JSON instead. This signals me that I should try again with a slight delay and see if the response has been computed in the meantime.
In other repositories, I’ve fixed some issues reported in support in the Algolia documentation, made the download size for algoliasearch-client-javascript lighter by using the files field in package.json (#528). I’ve also made the console.log ascii art at algolia.com/dashboard and algolia.com show up as a monospace font on all browsers. The change needed for that look like this:
@@ -203,7 +203,7 @@
console && console.log(
- "Built With:\n" +
+ "%c Built With:\n" +
"\n" +
" oooo oooo oo \n" +
" ooooo oooo ooooo ooooo \n" +
@@ -221,7 +221,7 @@
" ooooooooooooo \n" +
"\n" +
" POWERFUL REALTIME SEARCH API BUILT FOR DEVELOPERS\n" +
- " http://www.algolia.com/console"
+ " http://www.algolia.com/console", "font-family: monospace"
);
Another thing I’ve done is adding OpenSearch to Yarn (#406). You will be able to read more about this and other UX changes in an upcoming blogpost on blog.algolia.com. Opensearch on Yarn looks like this:
So happy that @espen_dev suggested to add opensearch to @yarnpkg! I use it all the time (yarn[tab] pkgname [enter]) pic.twitter.com/jmEYIaLfQr
— Haroen Viaene (@haroenv) March 15, 2017
This feature is built into all modern browsers, and I hope to add this to a lot of sites and see it more often. In short it’s adding a link href=search to the head of your page, and adding an xml document with some metadata. I’ll update this post to link to the post on Algolia when it’s been posted. Meanwhile you can use this awesome page on Mozilla developer network (MDN).